youtube深度学习推荐经典论文中关键点
前两天面试了一个候选人,他们其中一个项目就是复现youtube的深度学习embedding召回方案,虽然说效果不好,以及挺多人用了说效果不及预期,但是挺多思路对现在推荐依然影响深远。
总体思路
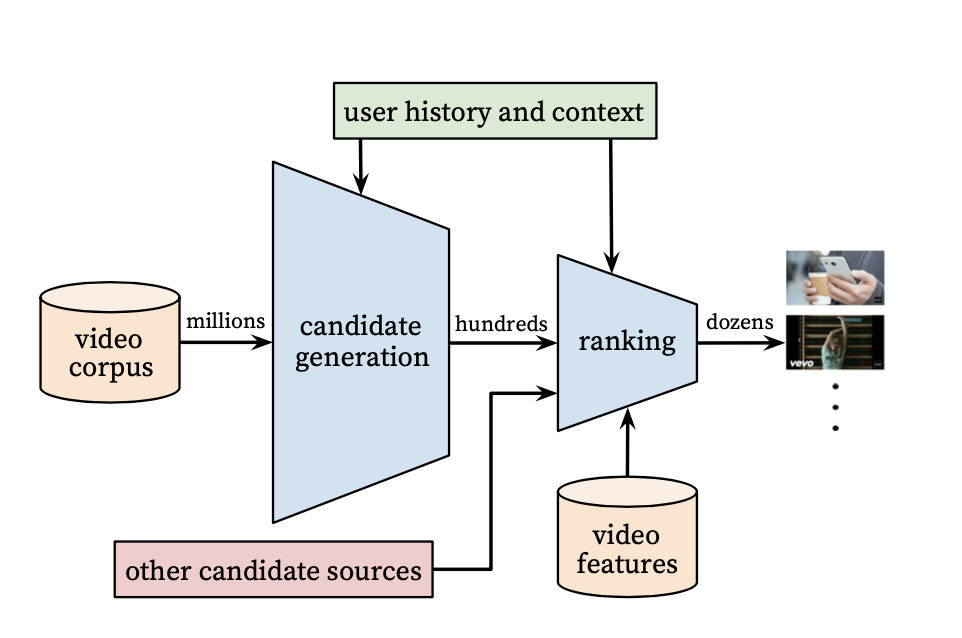
也是正常的分两阶段,第一阶段负责召回,在这里叫candidate generation,后一阶段负责ranking。
这里有两个先进点,这篇论文是16年9月发的,当时大家都在普及用协同过滤,文章提出了ranking,另一个是两阶段都是用深度学习。
candidate generation
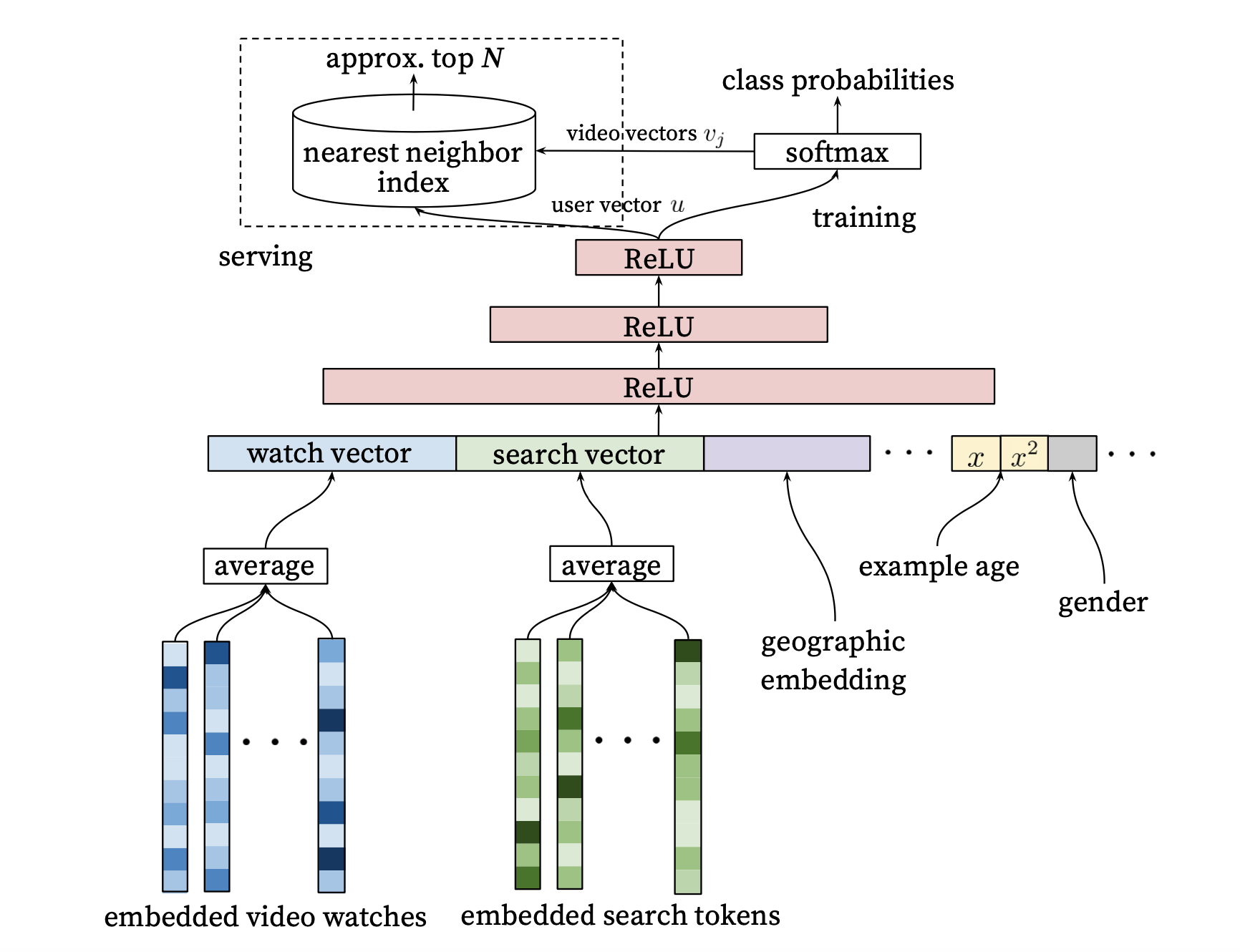
从下面往上面说吧,最下面特征包括四部分,第一部分是用用户看过的video的embedding做平均输入到网络,第二部分是用用户搜索过的词的embedding,第三部分是用户地理位置embedding,最后一部分是用户基础信息拼到一起,这里比如年龄,性别等。
至于上面的预处理embedding技术就是基础的word2vec的思路,video的embeding比如常见的行为序列embeding。
然后经过四个ReLU层,最后一层就直接是当前这个用户的embeding,如图右上角,接了一个softmax多分类器,这里的分类结果对应的是物料的数目,就是当前用户点击过的video,比如点击率10个,那么每一个是1/10,剩下的所有物料为0,整个这样训练,最后网络的连接从最后一层user embedding到item的总数目N,就会得到一个E*N的一个矩阵,这里E是表示中embedding的宽度,整个训练完之后矩阵的每一列都是一个长度为E的embeding,代表当前第k个video的embedding。
这里看着是不是很想word2vec的思路,其实基本上就是借鉴了word2vec的思路,word2vec是2013年提出来的,当时正是火热的时候,而且现在来看,word2vec的思路对推荐的影响还是很大的,不管是直接对文章之类用doc2vec直接向量化,以及item2vec中用行为序列向量化,以及现在graph embedding都有它的身影。
然后在说一下训练的过程吧,我们可以看到这个网络,输入就是前面说的四类特征,而输出就是当前用户对所有文章有没有点击。
- 所以第一步是先对video进行embedding化,这个有很多方法
- 对每一个用户的文章embedding做平均处理成网络想要的输入格式,以及输出中那些item是非0的也就是有点击的。这里的每一个用户的数据集就是一个训练样本。
- 用这些训练样本对网络进行训练,去拟合,调参
- 把最后一层网络到最后所有item的边的学习到的权重拿出来,就是前面说的每个item的embedding,然后输入到向量检索工具。至此训练结束
- 线上请求来了之后先经过网络到最后一层,然后最后一层的结果作为用户的embedding,去用它在向量检索工具中检索和它最相似的文章左右当前用户的召回
ranking
![]()
还是从下往上说吧,这里特征主要有四类
- 预估视频的embedding,以及用户最近点击过的n个视频的embedding的average
- 用户语言的embedding和当前视频语言的embedding
- 自上次观看同channel视频的时间
- 该视频已经曝光给用户的次数
其实看起来特征还是很简单的,他把所有的物品特征都表示在了embedding中,然后把用户的所有特征都表示在了用户最后点击过的视频embedding的average中。后面两个特征应该是观察业务数据之后加上去的特征,给我们提供了一个模型做特征的思路,线上最主要的,然后在根据业务分析数据去加特征,而不是一下子就都堆上去。
这里也说一下训练和预估的过程
- 和我们现在所有预估模型训练的思路一样,每一条行为日志都是一个训练样本,首先拿到训练样本和对应上面的特征
- 然后训练学习网络中的参数
- 用学习到的参数去上线做预估
关键点
先说三个最大的点吧
- 做推荐的时候从顶层设计,也就是把召回和排序放在一起去考虑设计模型,比如上面排序的时候基本上没有用用户基础信息特征,因为在召回的时候已经考虑过了,所有召回出来的video都是满足用户基础信息的video
- 做特征的时候从简单做起,基本上召回和排序中都只用了四类特征,而且都是最最主要的特征。这和我们平常做模型所有已经有的特征都堆上去的思路恰好相反,加特征的时候尽量从业务以及实际数据中的表现来考虑加
- 在召回的时候没有直接用模型直接预估,而是转化为向量检索。主要是从性能角度考虑,召回的数目和ranking的数目不一样,动则就上万,直接用模型预估的话太耗费时间了,同时也给现代推荐召回提供了一个很好的思路。另一个点是这样做用户的物品的embedding是有关联的,活着说物品是基于用户的行为学习的,而且这个模型初始的物品embedding对最终结果影响很小,只要能区分出来每个物品就行。
其次,其中的一些特征设计的很巧妙,我们可以借鉴
- 最主要的就是embedding的思路,当然这篇文章也是受word2vec的影响,到了现在做推荐就万物皆embedding的程度,好处是表示能力强,能够做到实时查询
- “Example Age”这个特征,训练的时候用(训练当前时间-请求时间),比如12小时前请求的视频,现在训练这个值为12,而再过10个小时做训练则这个特征值就变成了22,表示的行为发生时间对模型的影响,而线上预估的时候给这个特征全部置0。为什么这个做呢?其实就是消除行为发生时间对模型影响的bias,让模型拟合的更合理,有一个直观的理解就是\(U_1\)在1个小时前点击\(I_1\)和24小时之前点击理论上对模型的影响是不一样的,我们现在常用postion特征基本也是这么用的,目的也一样。
- 上次观看同channel视频的时间,这个特征,隐含的猜想是如果当前用户看了一个NBA,很可能接下来也会接着点NBA,而且现在用youtube依然能发现现在也是这个推荐的。
- 视频曝光给用户的次数,这个其实仔细想想还挺有意思的,首先他们没有像我们大众做法一样,直接做展示去重,隐含猜想是之前没点击过的视频之后依然可能会点击,只是随着曝光次数增大点击的概率会减小,瞬间感觉很合理。
还有是一些处理细节
- 对softmax物品数目过多复杂度过高的问题,基本上用了word2vec一样的解决方案,Hierarchical Softmax 和 Negative Sampling,这里就不细说了
- 优化目标不是点击率,而是平均播放时间,这个是结合业务定的。
基本上随着对这个行业的了解越深,发现这些经典论文真的是经典论文!
💬 评论(使用 Giscus,登录 GitHub 即可发言)